About Me












I am currently a Master's student in Data Science (2024-26) at the Dept. of Advanced Computing, Alliance University from 2024 to current. I was also a Summer Machine Learning Research Intern (2025) at i2CS Research Group, Indian Institute of Information Technology (IIIT) Kottayam, India. Currently, I am conducting research in the field of generative AI for healthcare applications supervised by Prof Jeba Shiney, as a part of my master's thesis. My research focus belongs to Machine Learning, Computer Vision, Natural Language Processing, and Generative Models, with applications to Medical Imaging and Clinical Decision Support. Previously, I enjoyed working with Dr Kala S (internship supervisor) under whom I carried out supervised research work focusing on the multi-modal alignment of Vision Language Models for Plant Disease Detection using Deep Learning. Conversely, some of my previous work and projects also determine my interest in Deep Learning for Natural Language Processing, Computer Vision and Explainable AI. Currently, at Alliance University, I am studying Deep Learning, Classical ML, ML Techniques for Image Processing, and Data Science taught by Prof. Mihir Dash, Dr. Vivek Mishra and Dr. Raj Dash . Moreover, I am a part of the Data Drishti (the data science club) at Alliance University as well. I finished my BSc in Mathematics and Statistics (Bachelor's 2021-2024) degree from Bangalore University, Bangalore in the silicon valley of India. I belong to the south part of India, from a city called Bangalore which lies in southeast Karnataka.
Water Your Repo, Grow Your Greens!
Recent Publications / Preprints
(Check Google Scholar for more)
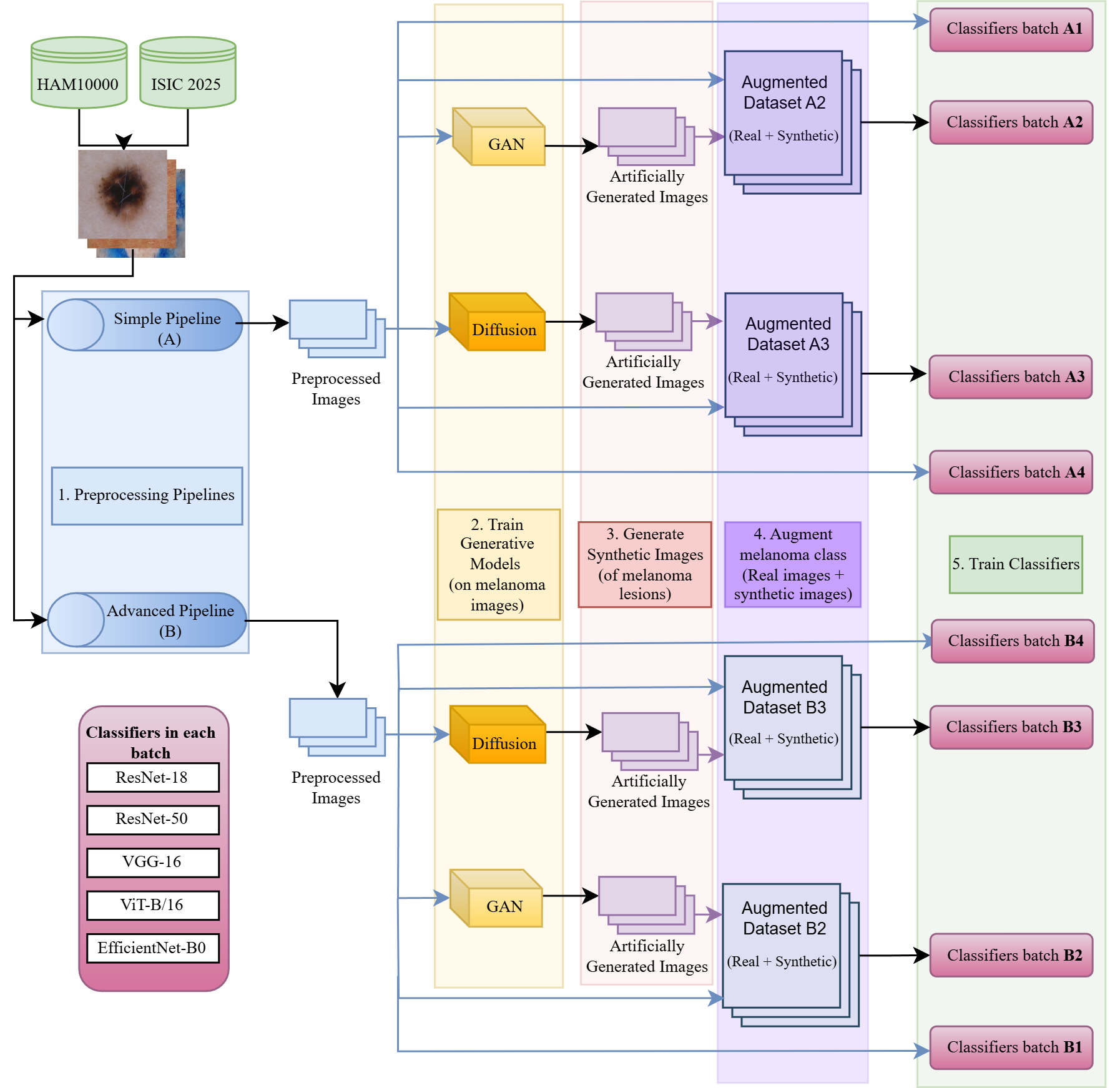
![]() SkinGenBench Generative Model and Preprocessing Effects for Synthetic Dermoscopic Augmentation in Melanoma Diagnosis
SkinGenBench Generative Model and Preprocessing Effects for Synthetic Dermoscopic Augmentation in Melanoma Diagnosis
Blogs
(Check Medium for more)
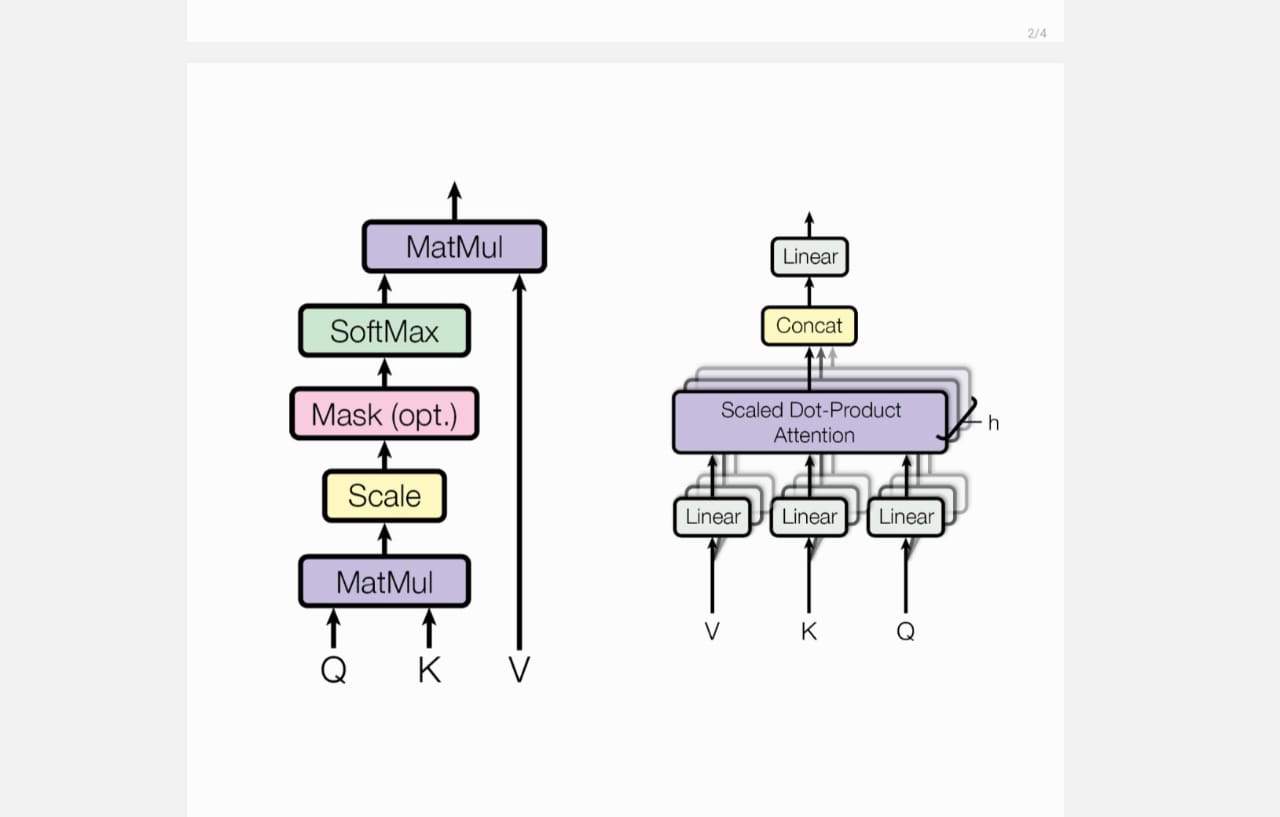
Attention-Mechanism A Detailed Study of Multi-Head and Grouped-Query Attention (GQA) Mechanisms
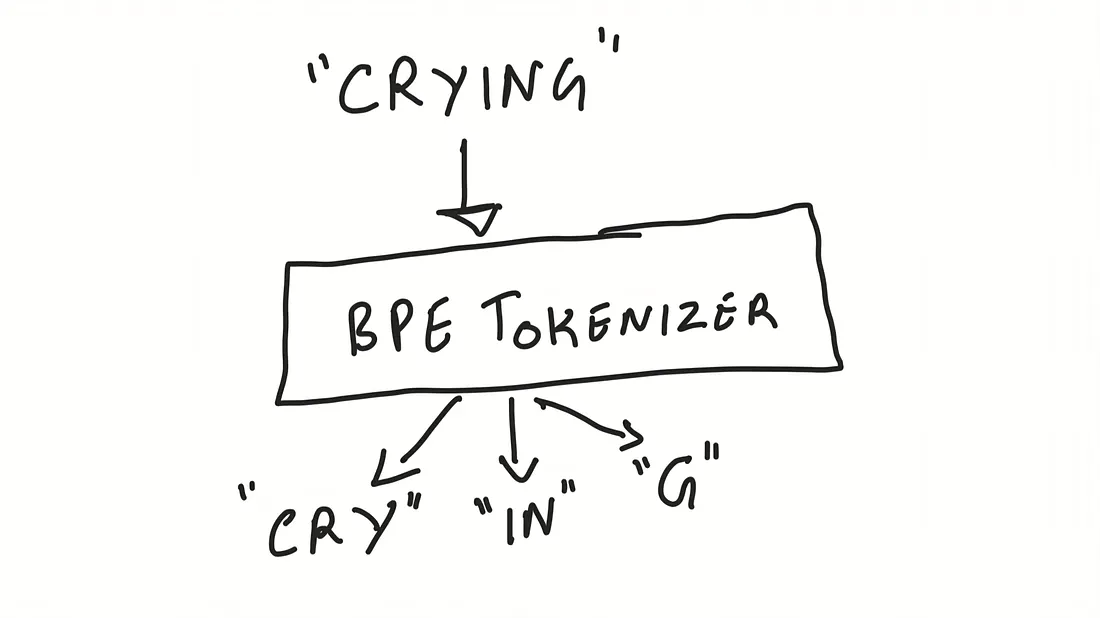
BPE-Tokenizer Implementing and Analyzing Byte Pair Encoding for Large Language Models
Projects
Built-from-Scratch Personalized Conversational AI (Ongoing)
Developing a modular conversational AI framework from scratch to emulate individual communication styles using personal chat logs.
The project includes end-to-end data preprocessing pipelines (extraction, cleaning, and custom BPE tokenization)
and a reimplementation of a LLaMA-style decoder-only Transformer. Incorporating QLoRA fine-tuning,
it demonstrates parameter-efficient adaptation and personalization in low-resource settings.
Code
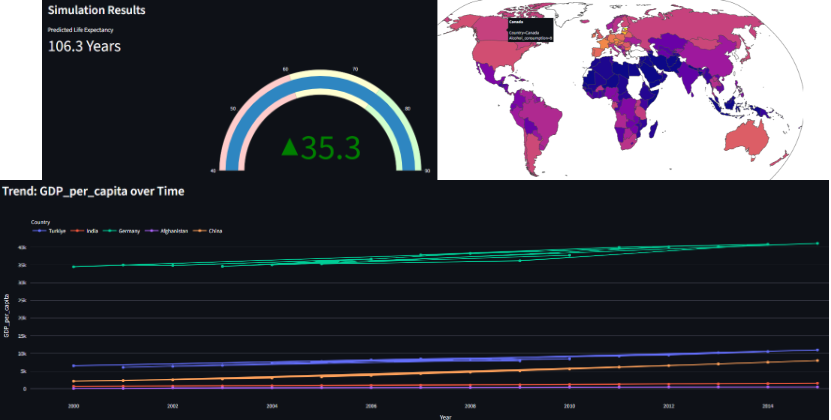
Life Exptectancy Modeling using WHO data
Built an end-to-end statistical modeling pipeline to analyze drivers of global life expectancy using WHO indicators across 2938 samples and 22 features. Applied feature engineering with VIF-based multicollinearity handling, sequential feature selection, and standardized regression modeling. Deployed a reproducible pipeline and interactive dashboard to quantify the relationship between socioeconomic-health variables and life expectancy, highlighting education, GDP, vaccination index, and BMI as strongest predictors.
Code
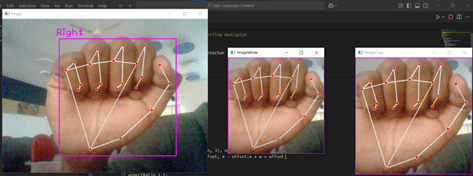
An End-to-End Sign Language Translation Pipeline from ASL Static Gestures to Fluent English Using T5
Developed an end-to-end system for translating finger-spelled American Sign Language (ASL) from static images into fluent English text. The pipeline combines hand gesture recognition with MediaPipe-based landmark refinement and a fine-tuned FLAN-T5-small model for natural language generation, enabling coherent and grammatically correct translations for assistive communication.
Paper Published!

LLaMA-style Transformer Reimplementation in PyTorch
Built a LLaMA-inspired large language model entirely from scratch in PyTorch,
implementing all core transformer components from first principles. Designed and analyzed multi-head attention,
grouped-query attention (GQA), and rotary positional embeddings (RoPE) to understand their role in token representation
and sequence modeling. This hands-on reimplementation provides an in-depth exploration of modern LLM architectures
and attention mechanisms.
Code
Blog
Academic and Research Experience
Here, you can find information about my research experience.
- Developed a Vision-Language Model (VLM) for descriptive plant disease diagnosis by integrating a CLIP ViT-Large with an InternLM2-7B LLM.
(Paper to be submitted for publication)
Letter of Recommendation
Education
Alliance University, Bangalore, India
Degree: Masters in Science
Major: Data Science
Year: 2024-current
Semester 3 GPA: 8.9/10 (currently in Semester 4) — Coursework in Machine Learning, Deep Learning, ML Techniques for Image Processing, and Data Science. Projects for the courses Deep Learning and ML Techniques in Image Processing include "An End-to-End Sign Language Translation Pipeline from Static Gestures to English" and Currently working on "AI-assisted skin cancer detection and classification research" which can be found in publications section as part of preprint.
Click for more!St. Joseph's College, Bangalore University, Bangalore, India
Degree: Bsc (Bachelor's in Science)
Major: Mathematics & Statistics
Year: 2021 - 2024
Contact Me
You can reach me via email at adarshpritam.ml@gmail.com. Connect with me on social media through the following profiles:
Open Source Contributions
For a complete overview of my open source contributions, check this GitHub search query. Below is the same information organized by year.